分布式运行环境
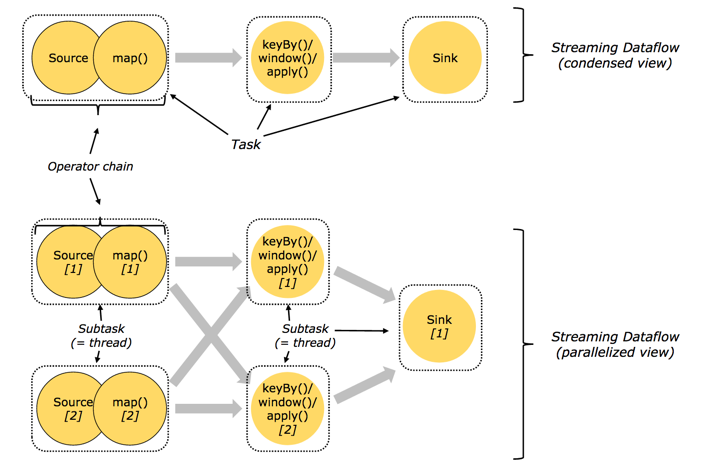
Task和Operator链
对于分布式执行,Flink的链式Operator将子任务合并成总任务。每个任务由一个线程执行。链式Operator变成总任务是一个有效的优化:它减少了线程到线程切换和缓冲的开销,并且在减少延迟的同时增加了吞吐量。 可以在API中配置Operator的链接行为。
下图中的示例数据流由五个子任务执行,因此具有五个并行线程。
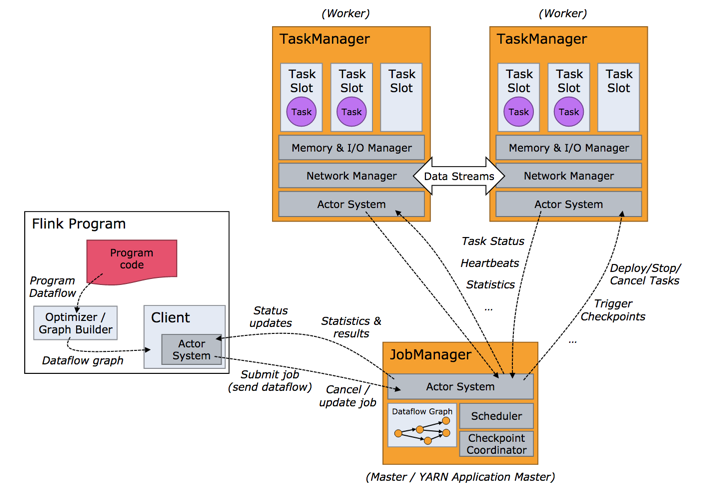
Job Managers, Task Managers, Clients
Flink运行时由两种进程组成:
- JobManagers(也称为master)协调分布式执行。它们安排任务,协调检查点,协调故障恢复等。至少有一个JobManager。高可用性设置将具有多个JobManager,其中一个始终是领导者,其他则处于待机状态。
- TaskManagers(也称为worker)执行数据流的任务(或更具体地说是子任务),并缓冲和交换数据流。必须始终至少有一个TaskManager。
JobManager和TaskManager可以通过各种方式启动:直接在机器上,容器中,或由YARN等资源框架进行管理。任务管理器连接到JobManager,宣布自己可用,并分配工作。
客户端不是运行时和程序执行的一部分,而是用于准备并发送数据流到JobManager。之后,客户端可以断开连接或保持连接以接收计算进度报告。客户端运行作为Java / Scala程序的一部分,触发执行,或在命令行执行./bin/flink运行。
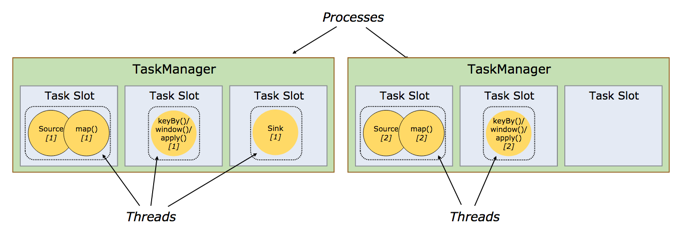
Task Slots 和 Resources
每个worker(TaskManager)是一个JVM进程,可以在单独的线程中执行一个或多个子任务。为了控制Worker接受多少任务,一个Worker被称为任务槽(至少有一个)。
每个任务槽代表TaskManager的固定资源子集。例如,具有三个插槽的TaskManager会将其管理内存的1/3用于每个插槽。插入资源意味着子任务不会与受管内存的其他作业的子任务竞争,而是具有一定量的保留托管内存。请注意,这里没有CPU隔离;当前插槽只分离托管内存的任务。
通过调整任务时隙的数量,用户可以定义子任务彼此隔离的方式。每个TaskManager拥有一个插槽,意味着每个任务组在单独的JVM中运行(例如,可以在单独的容器中启动)。拥有多个插槽意味着更多的子任务共享相同的一个JVM。相同JVM中的任务共享通过TCP连接(通过复用)和心跳来保持。当然还可以共享数据集和数据结构,从而减少每个任务的开销。
默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自相同的作业,也可以共享。 结果是一个插槽可以容纳整个工作管道。 允许这个插槽共享有两个主要好处:
- Flink集群需要的任务插槽要与作业中使用的最高并行度完全相同。 不需要计算一个程序总共包含多少任务(具有不同的并行性)。
- 更容易获得更好的资源利用率。 没有槽分配,非密集的source/map()子任务将阻止与资源密集型窗口子任务一样多的资源。 通过槽分配,我们将示例中的基本并行度从2增加到6,可以充分利用时隙资源,同时确保重要子任务在任务管理器之间平均分配。
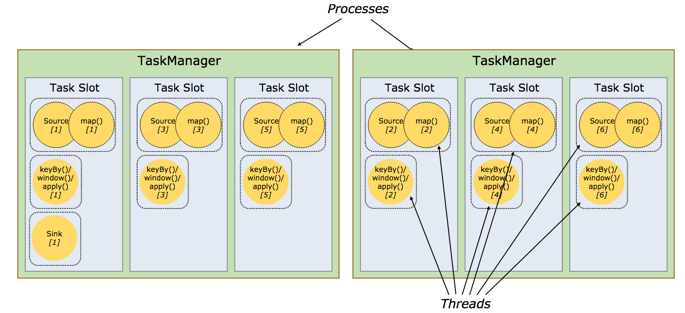
这些API还包括一个资源组机制,可用于防止不需要的时隙共享。
按照以往经验,任务插槽的较好默认数量是CPU内核的数量。 使用超线程技术,每个插槽需要2个或更多的硬件线程。
状态后端
密钥/值索引存储的数据结构取决于所选的状态后端。 一种状态后端将数据存储在内存中的哈希映射,另一种状态后端使用RocksDB作为键/值存储。 除了定义保存状态的数据结构之外,状态后端还实现逻辑以获取键/值状态的时间点快照,并将该快照存储为检查点的一部分。

Savepoints
使用Data Stream API编写的程序可以从保存点恢复执行。 保存点允许更新程序和Flink集群,而不会丢失任何状态。
保存点是手动触发的检查点,它们记录程序的快照并将其写入状态后端。 他们依靠这个常规的检查点机制。 执行过程中,定期在工作节点上快照并生成检查点。 需要恢复的时候,只需要最后一个完成的检查点,一旦新的检查点完成,可以安全地丢弃较旧的检查点。
保存点与这些定期检查点类似,不同的是它们由用户触发,并且在较新的检查点完成时不会自动过期。(类似于游戏的自动和手动存档)