DataStream API概述
Flink中的DataStream程序是对数据流进行转换的常规操作(例如,过滤,更新状态,定义窗口,聚合)。
数据流最初是从各种来源(例如,消息队列,套接字流,文件)创建的。 通过接收器返回结果,例如将数据写入文件或标准输出(例如命令行终端)。
Flink程序以各种上下文运行,独立或嵌入其他程序中。 Flink程序运行在本地JVM或许多机器的集群上。
示例代码
流式处理WordCount的代码:
Java:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
Scala:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object WindowWordCount {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999)
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
counts.print
env.execute("Window Stream WordCount")
}
}
运行方法:
开一个netcat窗口,并输入一些字符:
nc -lk 9999
正在运行的WordCount程序会接收到端口9999的消息并计算。
数据流转换
注:由于GitBook表格中不能贴代码,所以以下内容没有代码示例。省略内容请参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/datastream_api.html
| 转换 | 描述 |
|---|---|
| Map | DataStream->DataStream,将一个元素转化成另一个元素 |
| FlatMap | DataStream->DataStream,可以将一个元素转化为一个或多个元素,例如,可以将句子转化成单个单词 |
| Filter | DataStream->DataStream,过滤 |
| KeyBy | DataStream->KeyedStream,将数据按key分区 |
| Reduce | KeyedStream->DataStream,合并数据 |
| Fold | KeyedStream->DataStream,另一种迭代函数 |
| Aggragations | KeyedStream->DataStream,各种聚合函数 |
| Window | KeyedStream->WindowedStream,KeyedStream数据类型时间窗口内的计算 |
| WindowAll | DataStream->AllWindowedStream,对所有数据按窗口分组 |
| Window Apply | WindowedStream/AllWindowedStream->DataStream,可以在窗口内定义迭代函数 |
| Window Reduce | WindowedStream->DataStream,对WindowedStream类型进行Reduce |
| Window Fold | WindowedStream->DataStream,窗口内的增量迭代 |
| Aggregations on windows | WindowedStream->DataStream,窗口内的聚合计算:sum,min,max... |
| Union | DataStream * N ->DataStream,多个DataStream合并 |
| Window Join | DataStream,DataStream->DataStream,类似db的join |
| Window GoGroup | DataStream,DataStream->DataStream,类似db的group |
| Connect | DataStream,DataStream->ConnectedStreams 合并流 |
| CoMap,CoFlatMap | ConnectedStreams中的Map和FlatMap |
| Split | DataStream->SplitStream,根据条件切割流 |
| Select | SplitStream->DataStream,从分割出来的流中选择 |
| Iterate | 迭代反馈 |
| Extract TimeStamps | 从流数据中抽取时间戳 |
物理分区
Flink提供了一系列分区API,如下:
| 转换 | 描述 |
|---|---|
| Custom partitioning | 用户自定义分区 |
| Random partitioning | 随机均匀分布 |
| Rebalancing (Round-Robin partitioning) | 分区元素循环,为每个分区创建相等的负载。 在数据偏移的情况下用于性能优化。 |
| Rescaling | 按照上下游操作来自动分配操作,如下图,上游有两个操作,下游有6个操作,那么会自动平衡分配下游的操作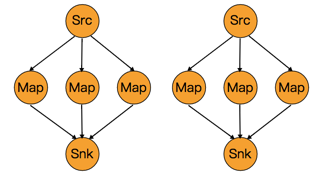 |
| Broadcasting | 广播到每一个分区 |
任务链和资源组
链接两个后续转换意味着将它们定位在同一个线程中,以获得更好的性能。 Flink会按照默认链接方式链接两个操作。可以通过API对链接进行粒度的控制。
如果要在整个作业中禁用链接,请使用StreamExecutionEnvironment.disableOperatorChaining()。 对于更细粒度的控制,可以使用以下功能。 请注意,这些函数只能在DataStream转换后才可以使用,因为它们的操作对象是之前的转换。 例如,您可以使用someStream.map(...).startNewChain(),但不能使用someStream.startNewChain()。
| 转换 | 描述 |
|---|---|
| start new chain | someStream.filter(...).map(...).startNewChain().map(...); |
| disable chaining | someStream.map(...).disableChaining(); |
| set slot sharing group | someStream.filter(...).slotSharingGroup("name"); |
资源组是Flink中的一个插槽,请参见插槽。
Flink Data Sources
数据源是Flink读取数据的来源。你可以通过StreamExecutionEnvironment.addSource(sourceFunction) 获取一个数据源。Flink读取数据源的方式有如下几种:
基于文件:
- readTextFile(path)
- readFile(fileInputFormat, path)
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)
基于Socket:
- socketTextStream
基于集合:
- fromCollection(Collection)
- fromCollection(Iterator, Class)
- fromElements(T ...)
- fromParallelCollection(SplittableIterator, Class)
- generateSequence(from, to)
常用:
- addSource 例如获取kafka数据源:addSource(new FlinkKafkaConsumer08<>(...)) 在Connector中会有更多介绍。
Flink Data Sinks
Flink提供如下方式保存数据:
- writeAsText() / TextOutputFormat
- writeAsCsv(...) / CsvOutputFormat
- print() / printToErr()
- writeUsingOutputFormat() / FileOutputFormat
- writeToSocket
- addSink